
Are Your Cloud Workloads Ready to Run from Another Region?
If your primary cloud region suddenly went offline, what would happen next?
Would your applications recover automatically — or would your team start rebuilding infrastructure manually?
Many organizations design for high availability within a region, but true resilience comes from being able to run your workloads from another region when things go wrong.
And that requires a well-designed disaster recovery strategy.
Why Disaster Recovery Must Be Part of Cloud Architecture
Modern applications rarely run on a single system. They typically depend on multiple interconnected components such as:
- Compute infrastructure
- Databases
- Storage systems
- Networking
- Application services and APIs
If the primary environment becomes unavailable, recovering each of these components manually can be complex and time-consuming.
A well-designed disaster recovery (DR) architecture ensures organizations can restore systems quickly and continue delivering services to users even during unexpected disruptions.
But the real question is: How quickly could your team restore your entire environment today?
What Multi-Region Disaster Recovery Looks Like
A common approach is to maintain:
Primary Region – running active workloads
Standby Region – prepared to take over during recovery
Data and configurations are replicated between regions so that the standby environment can restore services when needed.
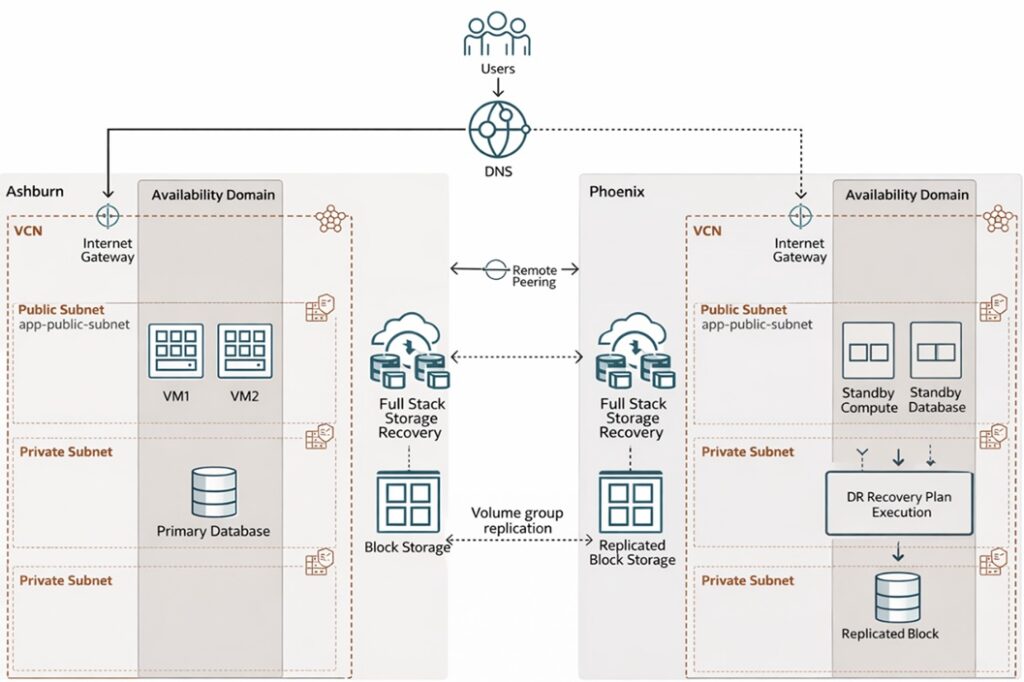
This architecture ensures applications can be recovered without rebuilding infrastructure from scratch.
How OCI Full Stack Disaster Recovery Simplifies Recovery
Full-stack environments involve many dependent components. Recovering them manually during an outage can be difficult.
OCI Full Stack Disaster Recovery (FSDR) simplifies this process by organizing infrastructure into disaster recovery protection groups and executing recovery plans.
Instead of manual steps, recovery plans orchestrate actions such as:
- Starting computing instances
- Activating standby databases
- Restoring application services
- Preparing networking configurations
This orchestration ensures that all application components recover in the correct order.
A Practical Way to Think About Disaster Recovery
Imagine your application environment includes:
- Two compute servers
- A database system
- Storage resources
- Networking configuration
Now imagine rebuilding all of this during an outage. How long would it take?
Now compare that with a predefined automated recovery workflow that can recreate the environment in another region.
That is the real value of automated disaster recovery.
Infrastructure Recovery Can Be Faster Than You Think
One of the biggest advantages of cloud-based disaster recovery is automation.
Instead of provisioning infrastructure step by step, predefined workflows can automatically perform tasks such as:
- Creating compute resources in the standby environment
- Executing recovery plans or DR drills
- Testing disaster recovery procedures safely
- Switching application services when needed
This enables organizations to recover environments significantly faster than traditional DR approaches.
Questions Every Organization Should Ask
Before implementing a disaster recovery strategy, organizations should ask:
- Do we have infrastructure deployed in another region?
- Is our data replicated or backed up across regions?
- Can our applications start automatically in a standby environment?
- When was the last time we tested our disaster recovery plan?
If these questions do not have clear answers, it may be time to review your cloud resilience strategy.
Designing Resilient Cloud Platforms
Organizations that successfully implement disaster recovery typically focus on four key principles:
- Multi-region architecture
- Data replication between environments
- Automated infrastructure recovery
- Regular disaster recovery testing
When these practices are implemented together, businesses can continue operating even when unexpected issues occur.
Final Thought
Disaster recovery is not just about preparing for worst-case scenarios. It is about designing systems that can recover quickly and continue delivering services even when disruptions occur.
Cloud platforms provide powerful tools to build resilient environments — but the responsibility of designing recovery strategies still belongs to the organization.
So, the next time you review your cloud architecture, ask yourself one simple question:
If your primary region stopped working today, how quickly could your systems run from another region?



